

내용중에 잘못된 부분이 있으면 의견 바랍니다.
먼저 mysql의 경우에 두가지의 메모리가 있다는 점을 먼저 알아둬야 합니다.
mysql의 경우 global 변수와 session 변수(또는 thread 변수) 두 가지 변수로 메모리를 컨트롤 합니다.
척 보면 아시겠지만 global 변수의 경우 mysql 데몬이 구동이 되면서 설정하는 변수들이며
session변수(per thread변수)는 client 가 접속할 때 마다 부여가 되는 변수 입니다.
따라서 메모리를 적절하게 부여하지 않으면 동시 접속시 과다한 메모리 할당으로 시스템에 문제가 발생할 수 있습니다.
자세한 변수들은 아래 페이지에서 확인할 수 있습니다.
변수 적용 범위가 both 인 경우에는 global로 설정하면 per thread변수와 같이 적용이 됩니다.
따라서 가급적으로 both인 변수들은 global 에 설정하지 말고 따로 mysql 서버에 접속하여 set 명령으로 할당하기를 권장합니다.
즉 /etc/my.cnf 에 both인 변수가 설정이 되는 경우를 주의 깊게 보시는게 좋을 것 같습니다.
1. mysql server 에 할당할 메모리 계산
global memory+(동시접속자수(max_connections* session buffers) : 시스템에 장착된 물리 메모리의 60%~80% 이하로 설정하는것이 좋다고 합니다.
예를 들면 DB 데이터 사이즈가 5G 라고 가정하면 디스크IO 를 줄이기 위해서 DB 전체를 global 버퍼에 넣고 약 300개의 동시처리를 하겠다면 대략 global buffer(6G정도)+(300* session버퍼들의 합)을 보고 서버에 적정한 메모리도 알수 있습니다.
일단 모든 OS는 메모리가 빵빵한게 최고입니다.^^
2. 변수 및 적정값
innodb 를 위주로 설명드리겠습니다.
값들을 설정할때는 mysql서버에 접속후 show variable 과 show status(show global status,show session status) 명령으로 서버 상태를 확인하면서 적절한 값을 찾아내시면 됩니다.
가급적 mysql서버가 구동이 된지 1~2일 지나서 status들이 갱신이 되어 있는 상태에서 확인을 하시는게 좋습니다.
max_connections - mysql서버에 접속할수 있는 최대 client갯수입니다. 1번 메모리를 할당량을 참고 해서 적절한 숫자로 설정하시면 됩니다. show global status like 'Threads_created%'; 하시면 mysql server에 최대로 생성됐던 클라이언트 수를 확인할 수 있습니다.
show status 결과중에서 Com_XXX 로 시작하는 값들은 모두 mysql 쿼리와 관련된 값이라고 보시면 됩니다.
create table,delete,insert,replace,select,show tables,show triggers,update 등등을 확인할 수 있으며
DB 서버가 읽기가 많은지 쓰기가 많은지 확인하면 됩니다.
그리고 다음으로 Handler_XXX 로 시작되는 값들은 튜닝에 중요한 정보를 제공해 주므로 반드시 한번씩 확인해보시기 바랍니다.
특히 아래의 값들은 잘 확인해 보시기 바랍니다.
* Handler_read_prev,Handler_read_rnd,Handler_read_rnd_next
위의 값들의 값이 시간에 따라서 계속 증가한다면 DB 테이블들이 설계가 잘못되어 있다고 보시면 됩니다.
특히 read_rnd 나 read_rnd_next의 경우에는 index 를 사용하지 않는 테이블들을 조인할 경우나 index key 없이 select 하는 경우등
이므로 테이블들 구조와 DB프로그램의 쿼리문들을 잘 살펴보시기 바랍니다.
* Key_xx 은 MyISAM DB와 관계 되는 값으로(Innodb에도 영향을 주는지는 확인하지 못했으니 확인부탁드립니다.)
Key_reads/Key_read_requests 를 계산해서 캐시 hit rate를 계산 할수 있습니다.
값이 높을수록 캐시가 잘되고 있다는 이야기 입니다.
Key_reads 값이 높다면 Key_buffer_size가 작다는 이야기 이므로 적당히 늘려주시면 됩니다.
* Qcache_XXX 값들은 query cache와 관계되는 값들로 아래의 값들을 유심히 확인해보시면 됩니다.
반복되는 쿼리에 대해서는 캐시에 저장했다가 응답하므로써 반응 속도도 높아집니다.
쿼리캐시 hir rate = Qcache_hits/(Qcache_hits+Com_select) 를 계산해서 100%에 근접한지 확인해보시면 됩니다.
mysql 서버를 막 시작하고 나서는 서버에 쿼리들이 실행이 안된 상태이므로 캐시히트률은 아주 작다는 점을 알아두시기 바랍니다.
서버에 DB프로그램에서 사용하는 쿼리를 계속 날려보시면 히트률이 증가하는것을 볼 수 있습니다.
* sort_buffer_size - status 값중에서 Sort_merge_passes값을 확인해서 이 값들이 계속 증가한다면 sort_buffer_size가 작다는 이야기 이므로 늘려주시면 됩니다. 제가 직 접확인해 본 결과 sort_buffer_size 가 커지면 디비 서버 성능이 상당히 감소 합니다.
따라서 가급적이면 global 변수보다는 session 변수로 할당을 해주시는것이 좋습니다.
Sort_merge_passes 값이 안늘어나는 상태까지 메모리를 줄여서 다른 곳에 할당해 주시면 됩니다.
ex) SET SESSION sort_buffer_size=값(my-innodb-heavy-4G.cnf 기본값이 8M입니다.)
벤치마크 테스트 결과입니다. 처리속도가 상당히 차이가 많이 납니다. QPS(query per sec)는 초당 처리한 쿼리갯수 입니다.
8M : QPS - 7506.51
32M; QPS - 4001.56
* Select_full_join, Select_range_check - show staus 결과 값이 0 이상인 경우에는 쿼리상 index 가 없이 table을 scan 하고 있다는 이야기 입니다.
따라서 이런 경우에는 반드시 테이블들이 index가 정상적으로 되어 있는지 및 DB프로그램에서 잘못된 join을 하고 있는지 확인해야 합니다.
* innodb_buffer_pool_size(global) - innodb를 위한 메모리 사이즈 입니다. DB전용 서버로 사용한다면 물리적인 메모리의 80%정도까지
잡아서 사용하시면 됩니다. 메모리에 모든 DB가 올라가 있는 경우 DB 데이터에 엑세스 할때 disk I/O를 최대한 줄일 수 있습니다.
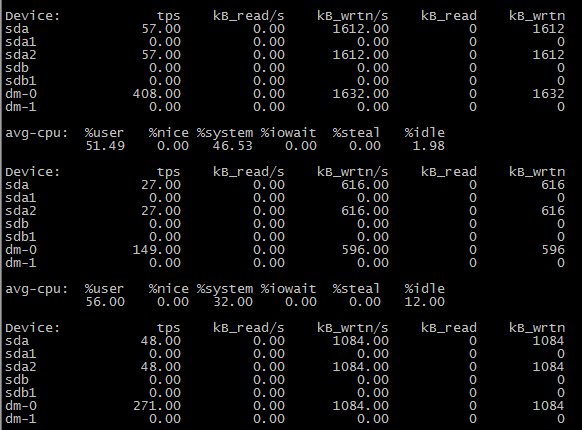
아래는 테이블 레코드 1000만건에 대한 select,insert,update 시의 io 입니다. read가 0 인것을 보실 수 있습니다.
* innodb_log_file_size(global) - innodb는 기본적으로 buffer에서 동작을 하며 모든 입출력의 관한 내용은 log 파일에 남기고
로그 파일이 모두 차면 실제 DB데이터 파일인 ibdataX 에 기록을 합니다. 따라서 로그 파일이 작으면 ibdata파일에 기록하는 횟수가 증가하게 됩니다. 사이즈를 키우면 IO를 줄일 수 있으나 사이즈가 커지면 디비가 크래시 됐을때 복구하는 시간이 길어집니다.
적당한 계산법은 사이트들 마다 조금씩 다릅니다만 innodb_buffer_full_size 의 25% 정도 설정하라고들 합니다.
* key_buffer_size(global) - MyISAM 테이블의 index 블럭 사이즈 입니다. MYISAM 만 사용한다면 서버의 물리적인 메모리에서 25%정도 할당하시면 됩니다. 이 값은 너무 크게 설정하시면 디비가 시작할때 디비를 읽으면서 페이징을 하게 되어 시간이 오래 걸리면서 시작이 됩니다.
* table_cache(global) - 모든 스레드에서 열린 테이블의 갯수 입니다. show status 결과중에서 opened_tables 값이 계속 증가하거나 flush tables 명령을 가끔 내리는 경우라면 table_cache 변수를 늘려주시면 성능 향상에 도움이 됩니다.
* thread_cache_size(global) - 쓰레드를 재사용하기 위한 값입니다. 클라이언트가 DB접속을 종료하더라도 쓰레드를 종료하지 않고 캐시에 저장하여 재사용하게 됩니다. 쓰레드생성비용을 줄일 수 있습니다. 접속이 많은 경우라면 아래와 같이 계산해서 캐시 효과를 누릴 수 있습니다.
쓰레드 캐시 히트률 계산 = 100-((Threads_created/Connections)*100)
* query_cache_size(global) - 쿼리 결과를 캐싱하기 위한 메모리양 입니다. 기본값으로 0 으로 잡혀 있으며 query_cache_type 이 0(캐시를 하지 않음)으로 되어 있어도 메모리는 할당됩니다.
* max_heap_table_size(session) - heap테이블 사이즈를 지정합니다.
* tmp_table_size(session) - 임시테이블 사이즈를 지정합니다.
위의 두 값은 disk IO와도 밀접한 관계가 있습니다. 기본적으로 heap,temp 테이블은 메모리에 생성하지만 사이즈가 초과되면 디스크에 생성하게 됩니다. created_tmp_disk_tables 와 created_tmp_tables 값으로 설정이 가능합니다.
* read_buffer_size(session) - 쓰레드당 full tables scan 을 하는 경우에 사용함.
큰 테이블이 많거나 범위에 대해서 scan 하는 경우 적당한 값으로 늘려줌
* join_buffer_size(session) - index 를 타지 않는 join할 경우에 사용함. 기본적으로 index없이 join하는 경우는 자제해야 하므로
쿼리를 수정하는 것이 나을듯 합니다.
SHOW GLOBAL STATUS LIKE 'Threads_created%'
294 (이부분은 서버에 따라 조금 다른 것 같습니다. DB처리가 빠른 장비일수록 숫자가 낮습니다)
===
Key_read_requests 314582337
Key_reads 9013
req / reads = 34,903
===
쿼리캐시 hit rate = Qcache_hits/(Qcache_hits+Com_select) = 0 ???
Qcache_hits 0
Qcache_inserts 0
Qcache_lowmem_prunes 0
Qcache_not_cached 479595331
Qcache_queries_in_cache 0
Qcache_total_blocks 1
Com_select 0
===
Sort_merge_passes 0
294 (이부분은 서버에 따라 조금 다른 것 같습니다. DB처리가 빠른 장비일수록 숫자가 낮습니다)
이 부분은 디비 서버가 생성한 쓰레드의 최대값이 들어갑니다.
즉 2cpu 의 경우에는 디비서버가 구동된 이후로 최대 동시에 297개의 쓰레드,297개의 클라이언트가 붙었다는 이야기 입니다.
key 캐시히트률은 req/reads 가 아니고 reads/req 로 계산해야 합니다.
쿼리캐시 히트율은 계산식은 맞습니다
쿼리 캐시를 enable 할려면 /etc/my.cnf 에
query_cache_type = 1 이렇게 잡아주셔야 쿼리캐시가 시작됩니다.
아니면 set global query_cache_type=1 해서 enable해주시면 되실겁니다.
com_select 값은 select 쿼리가 실행이 되면 늘어날텐데 이상하군요.
부하가 몇배 더 심한 서버의 경우에도, 장비가 좋으니 최대 client 갯수가 작습니다.
SHOW VARIABLES LIKE 'have_query_cache'
have_query_cache YES
query cache는 enable되어 있습니다. 기본으로 yes이고 disable 하려면 cache size를 0으로 해야 합니다.
현재의 query cache size는 128mb 입니다.
그런데... query_cache_type이 OFF네요.
헉. 기본이 ON인데, 왜 OFF?
/etc/my.cnf에서 ON으로 변경 했습니다.
다른 서버들도 체크해 봤는데, 2CPU 서버만 OFF네요.
query cache를 ON하니, 확실히 빨라지네요.
query cache가 OFF가 된거는 첨 봤는데... 아... 당황스럽네요. 왜 그런지.
하루 더 지나봐야 하겠지만, CPU의 부하가 현저히 줄어들었네요.
현재의 상태라면, 동접 1,000까지도 버텨줄 것 같은 느낌이 듭니다.
어느버전부터 그랬는지는 모르겠지만 query_cache_type 기본값이 off 입니다.
캐시사용하면 아무래도 부하가 많이 줄어들수 밖에 없겠죠
2cpu서버 사양 정도면 동시접속 1000정도도 무난하지 않을까 예상해봅니다.
로드가 많이 줄었다니 다행입니다.
가끔 mysql이 컴파일될 때 이상하게 되는거 같더라구요.
지난번에는 inno db가 없이 컴파일도 된거를 봤는데...
DB와 서버의 상태에 따라서 50%에서 80%까지 바꿔보면서 최적의 상태를 찾아야 하더라구요.
key_buffer_size 이것은 inno DB를 쓰는 서버에서는 굳이 높일 이유가 없습니다.
그냥 기본 값으로 둬도 충분할 것 같더라구요.
5.5.4부터 들어간 설정값이 있는데, 이것을 쓰면 메모리 사용량이 현저히 줄어들게 됩니다.
그런데 어떻게 잡아야 하는지... 그것은 아직도 잘 모르겠습니다.
innodb_buffer_pool_instances = 8
http://dev.mysql.com/doc/refman/5.5/en/innodb-parameters.html#sysvar_innodb_buffer_pool_instances
This option takes effect only when you set the innodb_buffer_pool_size to a size of 1 gigabyte or more. The total size you specify is divided among all the buffer pools. For best efficiency, specify a combination ofinnodb_buffer_pool_instances and innodb_buffer_pool_size so that each buffer pool instance is at least 1 gigabyte.
http://dba.stackexchange.com/questions/194/how-do-you-tune-mysql-for-a-heavy-innodb-workload
I learned something amazing about MySQL. If you allocate a single monolithic InnoDB Buffer Pool that is bigger that Total Installed Divided By Number of Physical CPUs, your will incite the OS to regular intervals memory swapping due to a full InnoDB Buffer Pool. MySQL 5.5's option known asinnodb_buffer_pool_instances can be used to split up the buffer pool. Yesterday, I properly implemented this for the client I mentioned in my answer last year. I still have 162GB for the client's Buffer Pool. I have set the server's innodb_buffer_pool_instances option to 2 because each DB Server is dual hexacore. I was thinking of setting it to 12 but then a colleague showed me a blog from Jeremy Cole on MySQL and Swappiness. After reading it, I put it into practice immediately for my client. I ran this command
temp table을 만들고, 그것에서 key들을 가져와서 작업 합니다.
oracle의 경우 DB set operation이 상당히 효율적인 것에서 착안한 것 입니다.
이 방법을 쓰면 5천만건이 넘는 DB에서도 빠르게 distinct 같은 것이 가능하죠.
$sql = " select wr_parent from $write_table where $sql_search ";
$sql_tmp = " create TEMPORARY table list_tmp_count as $sql ";
$sql_ord = " select distinct wr_parent from list_tmp_count ";
@mysql_query($sql_tmp) or die("<p>$sql_tmp<p>" . mysql_errno() . " : " . mysql_error() . "<p>error file : $_SERVER[PHP_SELF]");
$result = @mysql_query($sql_ord) or die("<p>$sql_ord<p>" . mysql_errno() . " : " . mysql_error() . "<p>error file : $_SERVER[PHP_SELF]");
$total_count = mysql_num_rows($result);