


안녕하세요. 공과대학에서 박사학위중인 학생입니다.
여러번 질문을 드린결과, 2 CPU + 2 GPU 시스템으로 워크스테이션을 구축할 예정입니다.
참고로 제가 사용하는 소프트웨어는 쓰레드 수가 많을 수록 유리하다고 알려져있습니다.
분자 시뮬레이션을 진행중이며 N x N body interaction 계산을 많이 수행해야합니다.
진짜 컴알못이라 며칠째 고민중이라 질문 드립니다.
본 질문
왜 CPU 속도의 증가폭에 비해 시뮬레이션 소프트웨어의 속도는 비례하지 않는가?
아래 그래프는 CPU의 성능 차이에 따른 분자시뮬레이션 소프트웨어의 성능 비교 그래프입니다.
Sisosoftware 사이트에서는 CPU간 속도의 차이를 볼 수 있었습니다. (From Processor Arithmetic)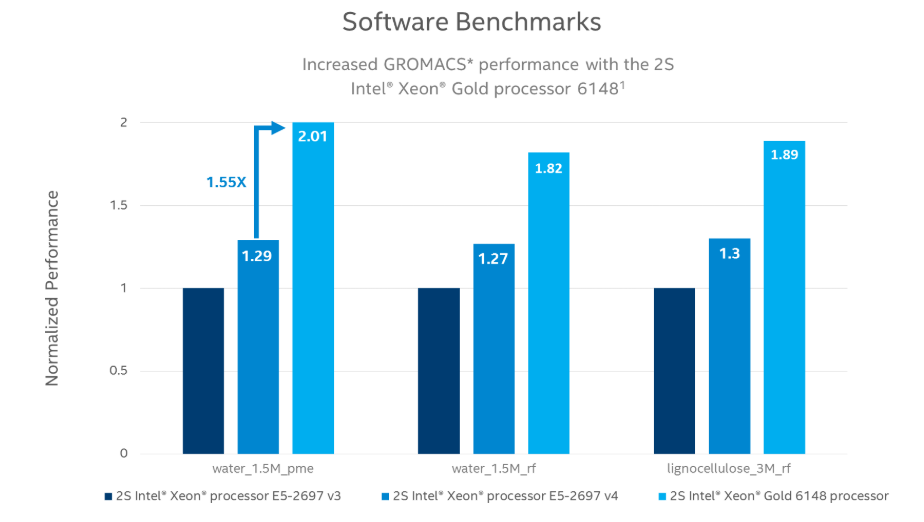



 그래프를 보시면 2697 v3 < 2697 v4 < 6148 로 갈수록 Perfomance가 1 < 1.29 < 2.01 로 증가하는 것을 볼 수 있습니다.
그래프를 보시면 2697 v3 < 2697 v4 < 6148 로 갈수록 Perfomance가 1 < 1.29 < 2.01 로 증가하는 것을 볼 수 있습니다.
하지만, 2697 v3 대비 Gold 6148이 Average score는 1.5배 증가해도 성능 자체는 2배이상 향상된 것을 볼 수 있었습니다.
Versus 사이트에서 Xeon 2697 v4와 Xeon Gold 6148을 비교하였을 때는 CPU 속도차이보다는
L2 CACHE 수치가 GOLD 6148 (빨간색이) 월등이 크다는 것만 알 수 있었습니다.
그래서 유추상으로는 L2 CACHE가 중요하구나 정도만 알았습니다.
추가적인 설명해주실분 있으시면 굉장히 감사하겠습니다.
(https://versus.com/en/intel-xeon-e5-2697-v4-vs-intel-xeon-gold-6148)
Intel Xeon E5-2697 v3
https://ark.intel.com/ko/products/81059/Intel-Xeon-Processor-E5-2697-v3-35M-Cache-2-60-GHz-
Intel Xeon E5-2697 v4
https://ark.intel.com/ko/products/91755/Intel-Xeon-Processor-E5-2697-v4-45M-Cache-2-30-GHz-
Intel Xeon Gold 6148
https://ark.intel.com/products/120489/Intel-Xeon-Gold-6148-Processor-27-5M-Cache-2-40-GHz-
앰버, 가우시안 등 요즘 대부분 프로그램들은 GPU 가속을 사용합니다. (CPU 보다 GPU가 중요합니다)
그리고 CPU에서 하나의 숫자를 가지고 1차원적인 척도로 성능을 정확하게 나타낼 방법은 없습니다.
캐시와 같은 마이크로아키텍쳐 부터 ISA, 클럭 등등 수 많은 비선형적인 요소들을 고려해야 하기 때문입니다
정확한 비교는 어떠한 워크로드가 주어졌을때, 그것을 수행하는데 얼마나 시간이 소요되느냐? <- 이렇게밖에 비교할 수 없습니다
싱글과 멀티성능의 구분은 제 경우에는 긱벤치를 많이 참조하는데, E5-2697 v3과 v4는 코어수는 v4가 4개 많지만 클럭은 오히려 낮아졌기 때문에
v4가 싱글과 멀티가 오히려 v3보다 떨어지는걸로 나옵니다. 물론 긱벤치에서 사용하는 몇몇 계산 알고리즘들이 사용하시는 어플의 연산과 다르고
다른 벤치와도 다르기 때문에 상대적으로 참고만 합니다만, 여튼 v3과 v4에는 성능차이가 거의 없다고 보고, 다만 Gold 6148로는 21%~24% 성능이
증가한걸로 확인되네요. 위 그래프의 2배를 인정한다면 긱벤치에서의 향상치보다 더 효율이 좋은것 같네요.
CPU모델명 (클럭, 코어수) 긱벤치 싱글 멀티
-----------------------------------------------------------------
E5-2697 v3 (2.6G, 14core) 싱글 3553 멀티 29713
E5-2697 v4 (2.3G, 18core) 싱글 3421 멀티 28001
Gold 6148 (2.4G, 20core) 싱글 4158 멀티 34868
E5-2697 v4에서 Gold 6148의 성능향상치 싱글 21% 멀티 24%
긱벤치 프로세스 벤치마크 http://browser.geekbench.com/processor-benchmarks
긱벤치 6148 싱글 및 멀티 벤치마크 http://browser.geekbench.com/v4/cpu/search?page=2&q=6148&utf8=%E2%9C%93
제온 E5-2600 V4 씨리즈 와 스케일러블 제온은 크기도 완전히 다르고 안에 하드웨어 명령어도 다르며 모든게 다 다릅니다..
스케일러블 제온이 현재 재일 마지막에 나온 제온이고 클럭보다는 코어 갯수에 치중되며 이에 따라 가상화 같은것에 사용된다고 봐야 합니다..
스케일러블 플레티넘도 있는데 대략 모델에 따라 개당 1500-2000만원쯤 합니다..
스케일러블 골드는 다나와에서 나온 가격으로는 600-700만원때가 가장 높을 것입니다..
www.cpu-world.com 에서 필요하신 프로세서를 비교하시면 좀더 자세한 정보가 나옵니다..
그리고 DP 때 퍼포먼스 차이 비교 같은 것은 인텔 기술부나 아키택쳐 박사급에게 문의해야 할 질문으로 보이네요..
도움좀 드릴까 검색좀 해봤습니다..
보통 멀티 쓰레드 지원하는 프로그램은 단순하게 .. 클럭 * 코어수 하셔서 비교 하시면 거의 벤치랑
맞아 떨어집니다.. 하지만.. cpu 세대가 같을때 이야기고 .. 세대가 높아질수록 같은 클럭에서
성능향상이 있으니 그걸 감안 하시면 될것 같습니다.. 말씀하신데로.. 1.5배 차이인데 벤치상에서
2배 정도 성능 차이가 나는건.. 캐시 때문은 아닌거 같습니다. 6148 제품에 보시면
Intel® AVX-512 를 지원한다고 나와있고 인텔에서 저 프로그램과 avx-512의 그래프를 가지고 홍보하고 있고
ftp://ftp.gromacs.org/manual/manual-2019-rc1.pdf 가장 최근 메뉴얼에 옵션 사항에 보면
avx-512관련 옵션이 있는걸로 보입니다.. cpu 의 명령셋을 활용하면 그 기능에서
수배 수십배가 빠르게 동작 하는걸로 알고 있습니다.. 그래서 저런 차이가 나는걸로 생각됩니다.
https://www.techpowerup.com/img/MAC0FcfwI0cO8pTQ.jpg 어디 자료인진 모르지만 이런 그래프도 있네요
그래서 제 생각은.. 만약 사용 하고 계시는 프로그램이 저 프로그램이거나 AVX-512를 지원하면 저것과 유사한
결과가 나올것이고 AVX-512를 지원하지 않는 프로그램이라면 저 그래프는 아무 의미 없어지고 ..
1.5 배면.. 1.5에 준하는 그래프가 나올꺼라고 생각합니다.
비관련자이니.. 그냥 참조만 해주세요.
gromacs 사이트에 가보면
Added AVX-512F SIMD support
This adds cpuid detection for AVX-512F and the low-level SIMD implementation. It is not yet present in any shipping hardware, but the knights landing version of Intel MIC will be the first CPU to support it, as well as future generations of their normal x86 CPUs (i.e., it merges MIC and x86 SIMD). The implementation currently only works with icc, and passes unit tests in the Intel SDE emulator. Some kernel kernel support functions are not yet implemented, and the instruction set will not be enabled automatically yet.
이렇게 나와있습니다. 위에 리플단 PDF에 512 활성화 하는 옵션도 있구요 .
AVX-512F 해택인 것 같습니다.
인텔 Advanced Vector Extensions 512( AVX-512) 개요
까다로운 워크로드를 위한 성능 향상
인텔® AVX-512는 과학 시뮬레이션, 금융 분석, 인공 지능(AI)/딥 러닝, 3D 모델링 및 분석, 이미지 및 오디오/비디오 프로세싱, 암호화, 데이터 압축 등의 워크로드와 용도를 위해 성능을 가속화할 수 있는 새로운 명령 집합입니다.
향상된 벡터 프로세싱 기능
초광대역 512비트 벡터 운영 기능을 갖춘 인텔® AVX-512는 가장 까다로운 컴퓨팅 작업도 문제 없이 처리할 수 있습니다.
애플리케이션은 512비트 벡터 내에서 한 클록 주기에 초당 32개 배정밀도 및 64개 단정밀도의 부동 소수점 연산을 처리할 수 있으며, 8개의 64비트 및 16개의 32비트 정수와 최대 2개의 512비트 FMA(Fused-Multiply Add) 유닛을 포함할 수 있습니다. 따라서, 이것은 인텔® Advanced Vector Extensions 2.0(인텔® AVX2)과 비교했을 때 데이터 레지스터 폭이 2배, 레지스터 수가 2배, FMA 유닛 폭이 2배에 해당합니다.
그래서 최상의 효율 내려면 계산 진행하실때 1CPU 코어수만큼의 쓰레드로 돌리는게 제일 좋을겁니다.