


안녕하세요. 일주일 전에 2cpu 가입한 초보 입니다.
그 동안 눈팅만 하다가 (유익한 내용들 많이 배웠습니다. 감사합니다!), 솔직히 말씀드리면 이게 너무 궁금해서 질문을 드리고자 가입했습니다.
제가 E5-26xx V4 시스템 중고에 대한 것을 알고 나서.. 한번 써보고 싶은 것을 못참고 조립을 했는데요.
- cpu: E5-2680v4 듀얼
- mainboard: Huananzhi X99-F8D Plus (실제론 C612 서버용 칩셋)
(중국제 메인보드 사면 안된다고 많이들 말리시는데도 샀다가 이 고생을;;)
- memory: Hynix HMA42GR7MFR4N-TF DDR4-2133(@2400) 16GB x8 쿼드
듀얼 cpu 구성인데, 양쪽 CPU가 각각의 remote RAM 접근시 latency/bandwidth가 이상합니다.
성능 측정은 PerformanceTest 11.0 버전 > advanced > Memory... 에서 한건데요.
| latency (random range) | NUMA node 0 | NUMA node 1 |
| NUMA allocation node 0 | 55.58ns | 55.58ns |
| NUMA allocation node 1 | 81.58ns | 80.88ns |
| block write speed | NUMA node 0 | NUMA node 1 |
| NUMA allocation node 0 | 3785MB/s | 3813MB/s |
| NUMA allocation node 1 | 2119MB/s | 2069MB/s |
cpu0, cpu1이 각각 다른 CPU에 붙은 (remote) memory 접근할때는 QPI 통과 delay가 생기는 건 알겠는데,
보시다시피 NUMA node 0 (cpu0) 쪽하고 NUMA node 1 (cpu1) 쪽하고 서로 대칭이 되는 결과가 아니라, 무조건 cpu1 쪽 메모리 접근할때만 latency, bandwidth 모두 큰 폭으로 나빠집니다.
두 소켓의 cpu를 서로 교환해봐도, 메모리를 서로 교환해봐도 결과가 같습니다.
그래서 저는 메인보드를 의심(소켓 불량? PCB 임피던스 문제?)하고 Aliexpress 셀러를 집요하게;; 괴롭혔습니다. ^^;
1. 셀러측에서 처음에는 듀얼 cpu를 사용하면 무조건 퍼포먼스가 떨어진다고 우기더니
(네, 보드에 cpu 하나만 장착했을 때, 45ns --> 두 개 다 장착 후 55ns로 이미 떨어지긴 했습니다.)
2. 제가 왜 한쪽(cpu1)만 더 떨어지느냐? 했더니,
CPU 별 서로 다른 PCI-E 슬롯이 연결되서 그렇다는 이상한 소리를 하다가,
(CPU에 연결된 PCI-E 디바이스가 IMC에도 영향을 주나요? 참고로, m.2는 0번 CPU 고정, 그래픽카드는 0/1번 어느쪽 cpu에 연결해도 문제 동일합니다.)
3. 제가 그것 때문에 저렇게 큰 메모리 접근 속도 차이가 날 수가 있느냐?했더니,
(아마도 셀러가 너무 귀찮고 짜증나서) 지네 메인보드 디자인 한계라고 환불해주겠댑니다.
근데 사실 동일 CPU인 시스템의 passmark/cinebench 등의 점수를 검색해서 비교해보면, 제 메인보드가 다른 X99/C612 메인보드/워크스테이션보다 점수가 많이 떨어지거나 하지는 않거든요.
(ASUS, 슈퍼마이크로, HP, ... Dell만 다른 벤더보다 좀 눈에 띄게 좋더군요.)
그러면 저런 비대칭 속도가 정상인건지? 그렇다면 어째서 그런지? 여전히 설명이 고팠구요. 다른 xeon e5-26xx v4시스템에서도 이렇게 cpu0/cpu1 양쪽 메모리 점수가 비대칭으로 나오는지 궁금하네요.
그래서 이번엔 다시 passmark에 물어보았습니다.
저는 내심 "passmark가 advanced > memory test 잘못하는거 아니야?"라는 의도도 있었는데...
하지만 passmark 관리자가 테스트 결과가 확실히 좀 이상해보이네? 한 것 외에는, 아무도 댓글을 달아주지 않네요. ㅠㅠ 아마도 이젠 구닥다리 e5-26xx v4 듀얼 구성따위 놀아보는 사람이 별로 없기 때문이겠지요.
앞서 퀘이사존에도 질문을 해봤지만, ( 2cpu는 이메일 인증 통과하기까지 시간이 좀 걸렸네요 ^^;) 역시 답이 없었습니다.
Passmark의 PerformanceTest 11.0 버전 > advanced > Memory... 에서
cpu 0/1 -- mem 0/1 4가지 경우에 대해서 latency랑 bandwidth 테스트 좀 부탁드려도 될까요?
테스트 방법은 아래 스샷 참조하셔도 되시고, 위의 passmark 쪽 링크에도 설명이 있습니다. 오래 걸리지 않습니다.
1. Passmark PerformanceTest 11.0 설치 후 실행, 탑다운 메뉴의 Advanced > Memory ...
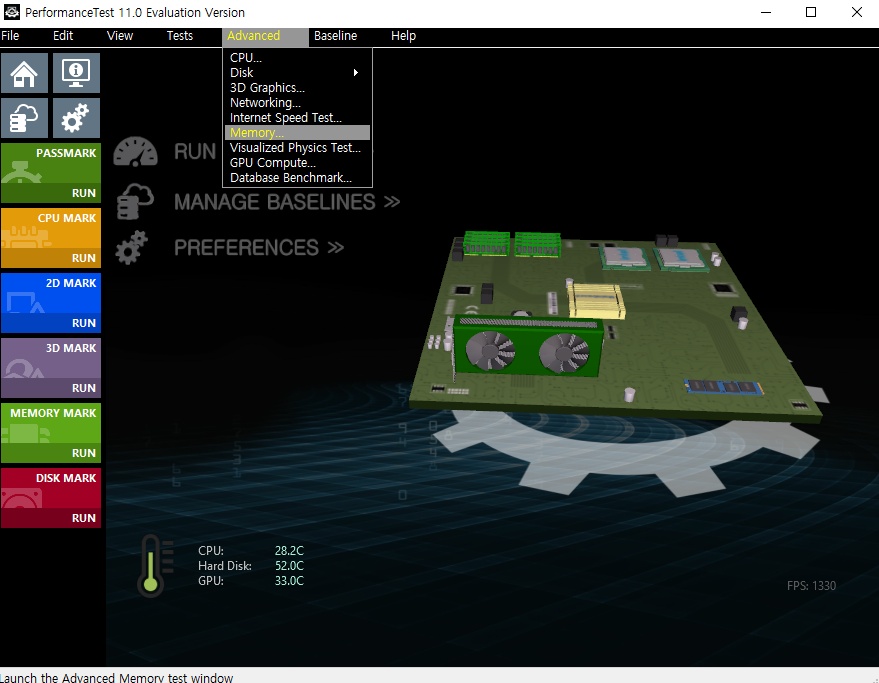
2. latency test를 numa node 0 / 1 , numa allocation node를 0 / 1 , 총 4가지 조합에 대해 수행하여 하단 random range latency 비교.
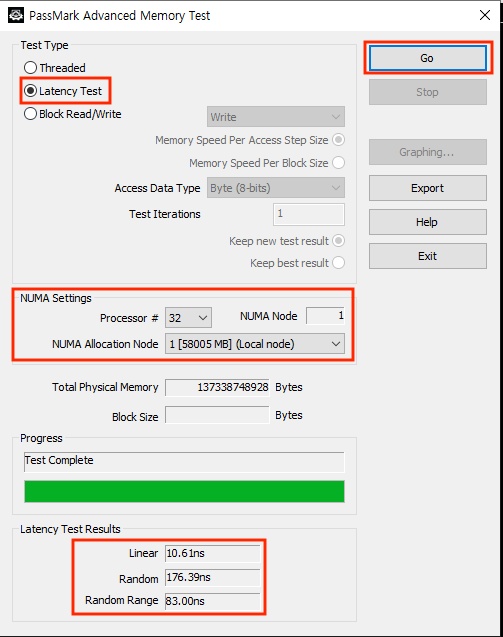
3. block write에 대해서 마찬가지로, numa node 0 / 1 , numa allocation node를 0 / 1 , 총 4가지 조합에 대해 수행하여 새 창에 표시되는 bandwidth 비교.
혹시 보유하고 계신 dual xeon e5-26xx v4 시스템도 mem0, mem1의 성능이 크게 다른건 아닌지 궁금하지 않으세요? ^^;
이젠 진짜진짜 더 이상 물어볼 곳도 없네요. ㅠㅠ
입출력 담당도 두 CPU 중에 한 CPU가 먼저 받아줄 것이며.
두 cpu 메모리 접근 속도가 차이가 난다에 별로 놀랍지는 않습니다.
CPU의 순차대기와 OS 커널의 간섭은 어쩔 수 없는 거 아닌가요 ??
그래서 요즘은 RDMA 를 사용하죠.
IP v6 를 기반으로 DRMA를 구현하여...... 직접 억세스 하고 싶습니다.
그 CPU 와 OS커널의 간섭이나 Delay 없이 다른 서버의 메모리에 접근하고 싶습니다.
RDMA 를 통해서..
다른 것들도 직업 억세스 하자는 움직임.
RDMA over NVMe
RDMA over NFS
RDMA over GPU
그리고 중국보드에 두 cpu의 접근속도 차이가 난다..는 질문은 무리 입니다.
메인보드가 싼거.. 당연히 기술적으로 부족하죠..
그게 완변하고 HP보드나 Dell보드와 비슷하다면 돈을 많이 받겠죠..
연산시에 정확하고 완벽한 동작은 IBM이 잘 합니다...
Lenovo 기계쪽을 보세요..
Thinkstation P900,P910,P920
X3650 M5
반대편 시퓨에 있는 PCIe는 딜레이 극악하게 늘어지고, 심지어는 같은 시퓨내에서도 코어에 따라 램 접근 속도차 납니다
그리고 멀티데스킹이므로 다른 요인도 배제 힘듭니다
보드 블럭다이어그램 보면 알 수 있습니다만
일반적인 듀얼마더보드의 구조상 첫번째 CPU에 부하가 더 걸리기에 첫번째 CPU의 온도도 더 높고 메모리 속도도 더 높습니다..
단 두 CPU의 차이는 그리 크게 차이나지는 않습니다.. (아마 많아야 10~15% 정도가 아닐까 추측해봅니다)
E5-2600V3/V4 가 나온지가 꽤 오래되어 단종된지도 꽤 되어서 재대로 된 보드 찾기가 쉽지 않습니다만
개인적으로는 중국 내수용보드는 보드라고 생각하지도 않고 사용하지도 않습니다..
개인적으로 좋아하는 보드는 미국향발 보드 (인텔, 슈퍼마이크로, TYAN) 정도 입니다..
Cpu mark 총점은 30,800점으로 ASUS, 슈마, HP 테스트 값들에 뒤쳐지지 않는데, 딱 저 테스트만 이상하게 나와요. ㅜㅜ
요새는 아무래도 대조군을 찾기는 힘들겠죠.
똑같은 프로그램 돌려서 결과값이 중국산 보드와 비슷하다면 문제는 없다라고 할 수 있지만
그렇지 않다면 중국산 보드는 어딘가 문제가 있겠지요..
그러나 그런 테스트를 돈들여서 한다는 것도 엔드유져에게는 쉽지 않고 내가 보기에는 이래저래서 문제다라고
중국 보드 제조사에 이야기 해도 그 문제를 해결해줄지는 모르는 문제입니다..
그나저나 부하가 걸린 쪽이 아마도 클럭이 높게 유지되고 있어서? 더 반응이 빠른가보군요. 또 유용한 정보를 배워가네요. 감사합니다. ㅎㅎ
제가 댓글에 적은 속도가 빠르다는 것은 부하를 100% 주었을때 메모리 동작도 동작할 수 있는 최대로 동작한다는 의미로
보시면 될 것 같습니다..
cpu는 2620 v4 입니다.
PerformanceTest 11.0의 advanced memory test는 NUMA node 테스트를 제대로 수행하지 못하는 것이었을까요?
한달 묵은 체증이 내려가는거 같습니다. 정말 감사합니다!!
=======================================================================================================================================
Intel(R) Memory Latency Checker - v3.11
Measuring idle latencies for random access (in ns)...
Numa node
Numa node 0 1
0 91.8 125.6
1 128.6 90.4
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 126783.9
3:1 Reads-Writes : 122172.0
2:1 Reads-Writes : 121868.1
1:1 Reads-Writes : 114215.6
Stream-triad like: 107334.5
Measuring Memory Bandwidths between nodes within system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Numa node
Numa node 0 1
0 64761.6 16684.5
1 16725.6 64444.8
Measuring Loaded Latencies for the system
Using all the threads from each core if Hyper-threading is enabled
Using Read-only traffic type
Inject Latency Bandwidth
Delay (ns) MB/sec
==========================
00000 210.29 128318.6
00002 210.81 128501.7
00008 211.57 128222.4
00015 211.70 128083.5
00050 199.87 127241.8
00100 183.51 125596.4
00200 121.22 92607.0
00300 110.09 63446.0
00400 104.28 48124.2
00500 100.70 38986.3
00700 97.13 28266.5
01000 97.98 19979.7
01300 93.68 15644.0
01700 92.60 12166.5
02500 91.72 8513.3
03500 91.03 6294.2
05000 91.36 4614.1
09000 91.05 2881.8
20000 90.88 1685.7
Measuring cache-to-cache transfer latency (in ns)...
Using small pages for allocating buffers
Local Socket L2->L2 HIT latency 39.7
Local Socket L2->L2 HITM latency 43.4
Remote Socket L2->L2 HITM latency (data address homed in writer socket)
Reader Numa Node
Writer Numa Node 0 1
0 - 97.9
1 98.5 -
Remote Socket L2->L2 HITM latency (data address homed in reader socket)
Reader Numa Node
Writer Numa Node 0 1
0 - 98.2
1 97.6 -
=======================================================================================================================================
제 생각에는 performanceTest 11.0의 advanced > memory ... 테스트가 cache hit 영향을 배제하지 못한게 아닐까? 싶은데 모르죠. ㅎㅎ
여하튼 multi processor 시스템에서 PerformanceTest 결과는 틀릴 수도 있다 정도로 참조하시면 될 것 같습니다.
UEFI 모드로 돌리면 메모리 속도 벤치마크 테스트 항목도 있을 것입니다..
근데 memtest86도 numa node 별 별도로 테스트 결과가 나오나요?
보통 시스템 1대 전체에 대한 것에 대해 나옵니다..
memtest86을 구글링하면 사용 방법이나 동작하는 많은 사진들을 볼 수 있을 것입니다..