

간단한 내용과 함께 BMT결과화면을 캡쳐하셔서 업로드 하시면 됩니다.
(SPEC Viewpert/Vray Rendering / HD Tune / HD Tach / CINEBENCH / CrystalDiskMark / IOMeter / AJA / 소비전력)
멀티 GPU 연산 컴퓨터에서 딥러닝 벤치 중의 하나인 FP16 resnet50 벤치와 octane 벤치가 PCIE 4.0 과 3.0에서 성능 차이가 나나 확인하기 위하여 비교 시험을 시행하였습니다.
사용된 컴퓨터 시스템은 다음과 같습니다.
1. CPU : AMD Epyc 7262 (8 cores/16threads) 3.2GHz
2. MB : Gigabyte MZ32-AR0
3. RAM : Hynix 16GB DDR4 2666MHz * 8 128Gbytes
4. Storage : Samsung 980 Pro 1TB
5. Graphic cards : Gigabyte RTX3080 blower 3 EAs & MSI RTX 3080 1EA
6. Power : EVGA 2000W & Supermicro 600W
7. OS : Ubuntu 22.04
8. Benchmark software : phoronix-test-suite octanebench & FP16 resnet50 benchmark
벤치마크 테스트 중 RTX 3080 blower 하나가 죽어 레노버 RTX 3080(MSI RTX 3080) 1개를 긴급 투입하여 시험을 진행하였습니다.
PCIE 4.0으로 테스트 후 바이오스에서 3.0으로 레인 속도를 변경하여 비교 테스트를 시행하였습니다.
결과는 아래와 같습니다.
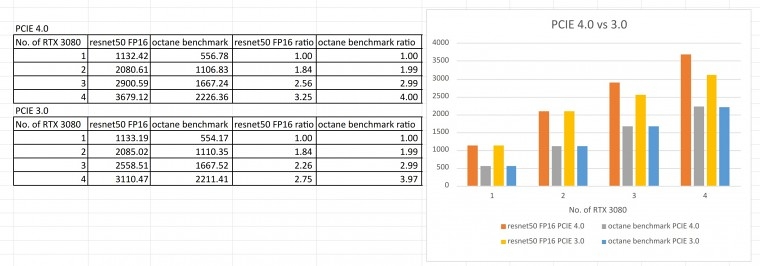
octane 벤치는 PCIE 3.0 및 4.0에 관계 없이 성능 차이가 거의 없습니다.
반면 딥러닝 벤치인 FP16 resnet50는 GPU 2개 까지는 성능이 같게 나오고 3개에서는 PCIE 4.0에서 PCIE 3.0에 비해 1개 GPU 성능의 30% 차이가 나고 4개인 경우 1개 GPU 성능의 50% 차이가 납니다.
octane 벤치는 PCIE 대역폭에 관계 없이 각각의 GPU에서 병렬 연산을 하기에 성능 차이가 없게 나오고, FP16 resnet50 벤치는 octane 벤치와 달리 PCIE 레인을 통한 메모리 대역폭이 연산에 영향을 주는 것 같습니다.
GPU간 데이타 전송 속도를 p2pBandwidthLatencyTest 프로그램을 이용하여 측정하였습니다.
4개 GPU에서 PCIE 4.0의 경우 단방향 11GB/s 양방향 15GB/s 이고, PCIE 3.0의 경우 단방향 6GB/s 양방향 9GB/s 입니다. latency는 PCIE 4.0 과 3.0이 비슷하며 오히려 4.0에서 일부 더 길게 나옵니다.
멀티 GPU를 이용하는 목적이 octane 벤치처럼 병렬 연산을 하는 경우 PCIE 3.0도 좋은 선택입니다.
하지만 딥러닝 연산을 하는 경우 RTX 3080에서는 GPU 2개 까지는 차이가 없으나 3개 및 4개에서 차이가 나기에 3개 이상의 멀티 GPU 딥러닝 연산 컴퓨터에서는 PCIE 4.0 x16을 지원하는 메인 보드를 이용하는 것이 좋겠습니다.
|
||||||||||||
|
||||||||||||
|
||||||||||||