


간단한 내용과 함께 BMT결과화면을 캡쳐하셔서 업로드 하시면 됩니다.
(SPEC Viewpert/Vray Rendering / HD Tune / HD Tach / CINEBENCH / CrystalDiskMark / IOMeter / AJA / 소비전력)
HPCG 프로그램은 슈퍼컴퓨터 벤치마크 프로그램으로 사용되며 메모리 대역폭에 의존하여 성능이 큰 영향을 받습니다. 즉, 메모리 대역폭이 클수록 연산 능력은 더 향상 됩니다.
제가 만든 듀얼 에픽 7551 연산컴은 CPU당 메모리 채널이 8채널로 듀얼인 경우 16채널 메모리가 됩니다. DDR4 2666V 메모리를 사용했지만 stream 벤치마크를 돌려보면 280 GB/s 정도의 메모리 대역을 보여 줍니다. 메모리 대역 성능은 거의 100퍼센타일에 가까운 성능 이기에 CPU 성능은 낮지만 HPCG 벤치마크 성능은 잘 나옵니다.
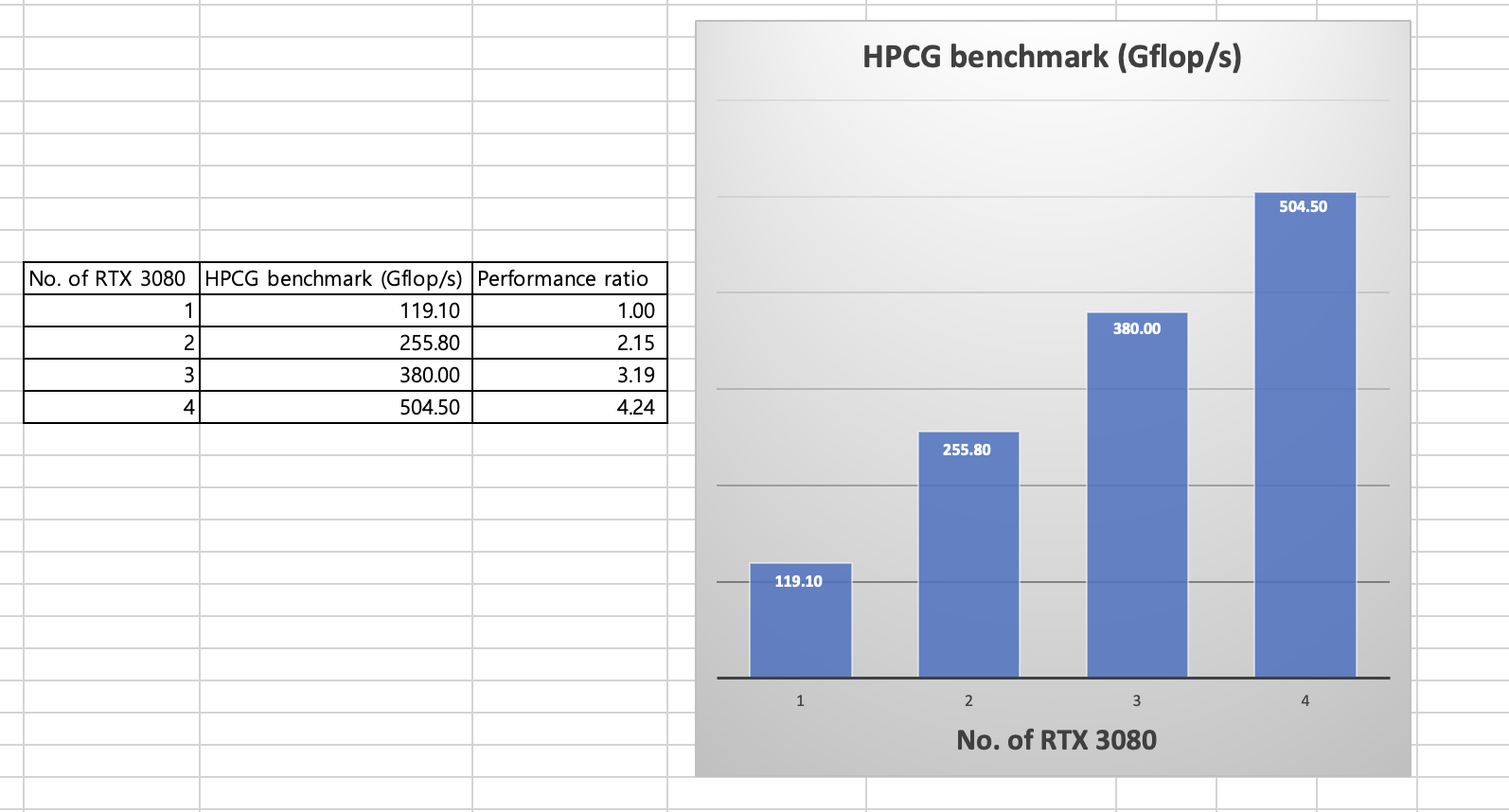
RTX 3080은 10GB의 메모리에 메모리 대역폭이 760GB/s 이기에 CPU에 비해 아주 우수한 HPCG 연산 능력을 보여줄 수 있습니다. RTX 3080 이 3080Ti 나 3090에 비해 메모리 대역폭은 떨어지지만 HPCG 프로그램이 우수한 scalability 를 보여 주기에 RTX 3080 4개를 이용하여 연산 능력의 성능 향상 정도를 측정해 보았습니다.
측정 결과 RTX 3080 4개는 A100 40GB 2개에 비해 더 우수한 성능을 보여 주었습니다( 504.5 GFlop/s vs 485.0 GFlop/s).
RTX 3080 의 딥러닝 연산 능력이 부족하기는 하나 과학적 연산 프로그램을 돌리는데 잘 활용될 수 있다고 생각합니다.
시스템 사양은 아래와 같습니다.
1. CPU : i9-10900X
2. MB : Gigabyte X299 WU8
3. RAM : Samsung 16GB DDR4 3200MHz * 8 128Gbytes
4. Storage : Samsung 980 Pro 1TB
5. CPU cooler : Thermalight Peerless Assassin 120
6. Graphic cards : RTX3080 4 EAs
7. Power : EVGA 2000W
8. OS : Ubuntu 22.04
9. Benchmark software : HPCG 3.1 Binary for NVIDIA GPUs Including Ampere based on CUDA 11 xhpcg-3.1_cuda-11_ompi-4.0_sm_60_sm70_sm80
X=256, Y=256, Z=256 60 초간 벤치마크 프로그램 실행 조건으로 테스트를 진행하였습니다.
참고로 A100 40GB 2 개 HPCG 벤치마크 결과는 아래 그래프와 같습니다.
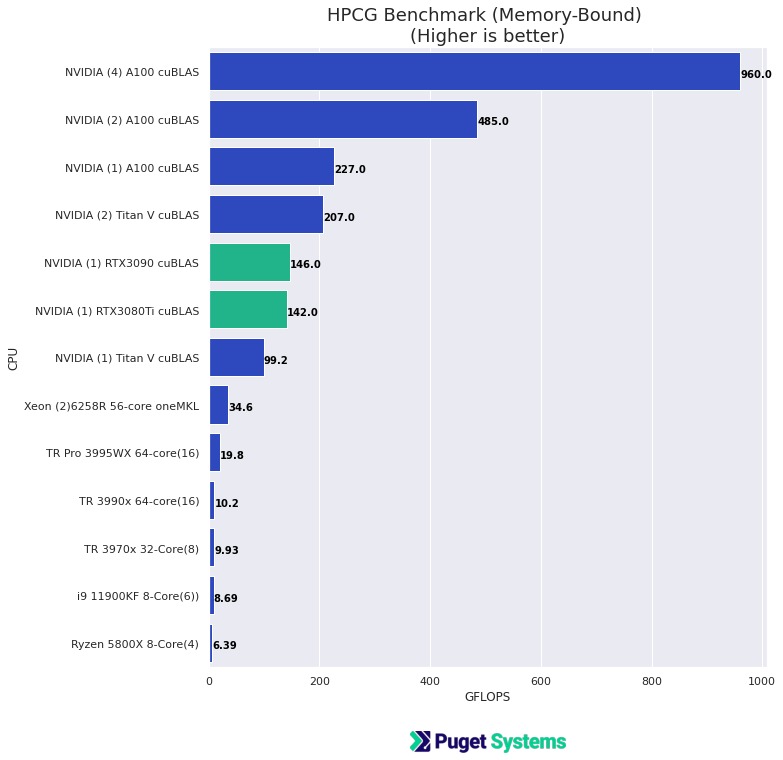
출처 : Outstanding Performance of NVIDIA A100 PCIe on HPL, HPL-AI, HPCG Benchmarks | Puget Systems