


[Server] Super GPU Box 가 드디어 완성되었습니다.
조회 8062 추천 1
https://m.post.naver.com/viewer/postView.naver?volumeNo=37880797&memb… (688)
https://www.TrueAI.kr/ (736)
요새 AI 가 뜨네, GPU 가 부족하네, 중국으로의 수출규제 때문에 용산에 4090 가격이 미쳤네, 전용 데이터 센터를 만드느라 전기가 부족하네 아무튼 전 세계적으로 이쪽 바닥이 난리도 아닙니다. 그래서 저는 2023년 10월에 True AI 라는 신규 법인을 설립하고 기존의 문제점을 어느정도 해결하면서 니치 마켓을 석권하고자 Super GPU Box 의 개발을 시작했고, 최근에 솔루션을 완성했습니다.
일단 사진부터 시작

이게 오늘 설명할 Super GPU Box 의 외관 입니다. 일반적인 42U랙 기준으로 2개 빠짝 붙여놓은 크기 입니다.
앞 커버를 열면 이렇게 생겼죠


양옆은 항온항습기(에어컨)이 한개씩 붙어있습니다. 총 냉방능력은 78000BTU 고 실외기는 따로 한개씩 총 두개 있습니다.
방온항습방음방진랙 답게. 문닫으면 40데시벨 정도의 낮은 스음이 장점입니다. 사무실이나 연구실에 충분히 둘만 하죠.
4U짜리 GPU 확장 케이스가 8대, 그리고 4U짜리 메인 서버가 1대 있습니다.
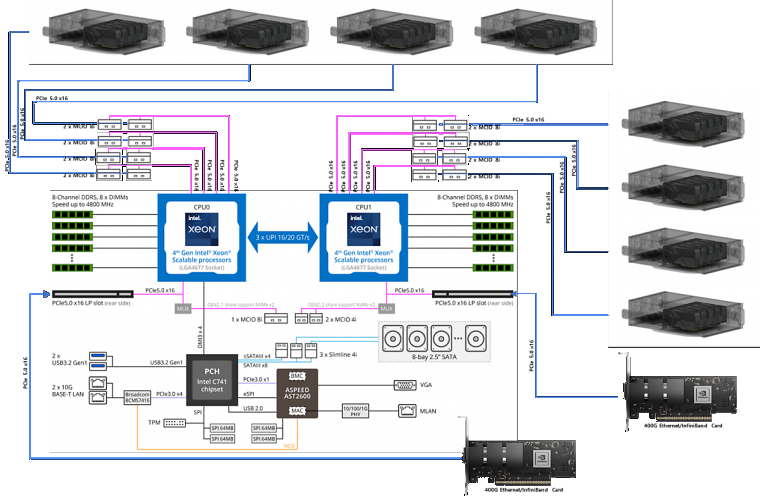
이 서버와 각 GPU 확장 케이스는 아래처럼 2개의 MCIO 8i 케이블로 연결됩니다.
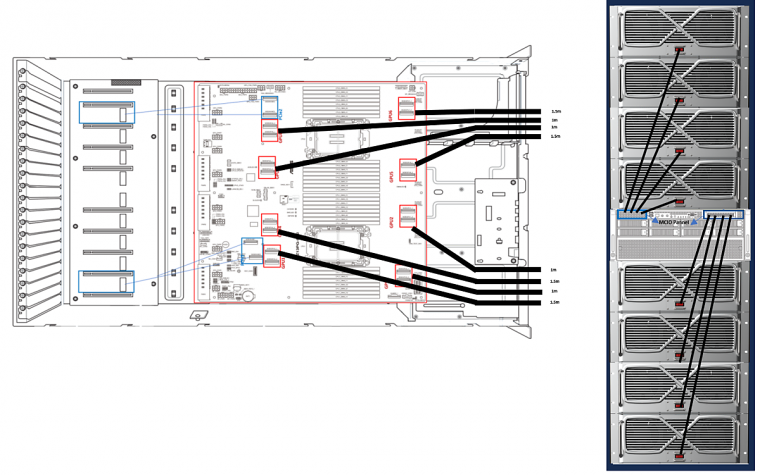
AMD 제노아나 인텔 스케일러블 4세대 듀얼 프로레서 기반의 서버를 사용하고, 총 16개의 MCIO 8i 포트를 이용해서 MCIO 8i 케이블 2개씩을 서버와 GPU 확장 케이스를 연결합니다.(저는 원래 파트너로서 인텔만 사랑합니다.)
물론 케이스부터 케이블, 컨넥터, 확장용 보드, 고전력 3+1 리던던트 전원공급 장치까지 다 설계해서 만들어 냈습니다. 특히 파워보드는 최대 2700와트 CRPS 4개를 이용해서 그중 3개의 합인 8100와트 까지 사용가능 합니다. 하지만 실제로 필요한 최대전력은 약 5000W 이하로서 충분한 안정성을 지닙니다.
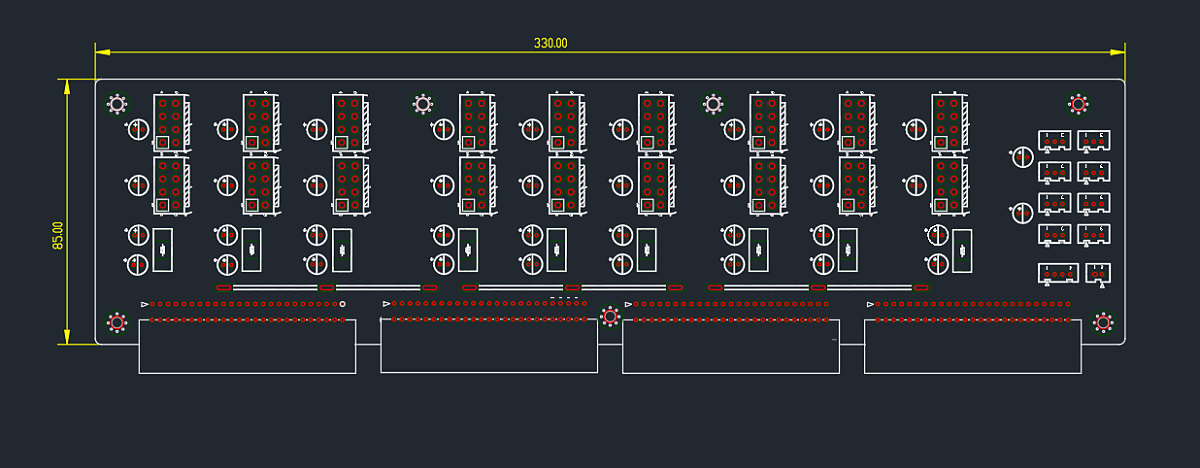




100Lane PCI-e Switch Chip 을 사용해 최대 5개의 PCI-e 4.0 x16 카드 5개를 장착하고 서버로도 동일하게 x16 으로 연결하는 전용 보드도 있습니다.

여기에 각 5개의 일반적인 뚱뚱이 게임용 GPU 를 장착하기 위한 전용 케이스도 제작했습니다. 각 4슬롯 간격이지요.




결과적으로 한대의 서버에서 40개의 GPU 를 모두 인식하고, 머신러닝, 시뮬레이션, 렌더링 등 멀티 GPU 를 이용한 다양한 어플리이션에 이용가능해 집니다.
보기엔 쉬워보이시죠? 이거 만만한 기술이 아닙니다.
일단 메인보드에서 40개의 GPU 인식부터가 안됩니다.
그걸 잘(?) 해결했다고 해도 이번엔 운영체제에서 인식이 안됩니다.
이것도 잘 해결했다고 치고.. 이번엔...쿠다같은 라이브러리들이 잘 될지 보장이 없죠.
이 모든걸 해결해 나간 결과물이죠. 궁금하면 한번 해보세요~ 되나~

기존의 고성능 GPU 서버들과 비교해 볼까요? 아래와 같은 종류의 GPU 서버들은 많이 보셨을 겁니다.



이런 서버들은 기본적으로 최대 연결 가능한 GPU의 수가 제한 됩니다. 공간때문이죠.
2Slot 용 GPU 라 하더라도 최대 10개를 넘기기 어렵습니다. 전력 때문이라도 보통 8개가 최대죠
그럼 성능을 단순 비교해 보겠습니다.

일반적인 머신러닝용 연산으로 비교하면 게임용 RTX4090과 엔터프라이즈용 H100 의 성능은 약 두배가 채 안됩니다.
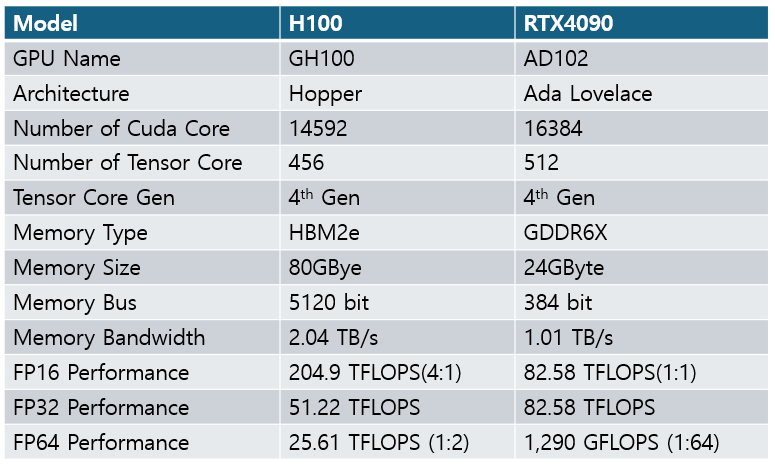
물론 아키텍쳐가 다르다지만 텐서코어는 같은 세대이고 숫자도 RTX4090이 더 많습니다.
이제 이것을 기준으로 단순 계산해 보면
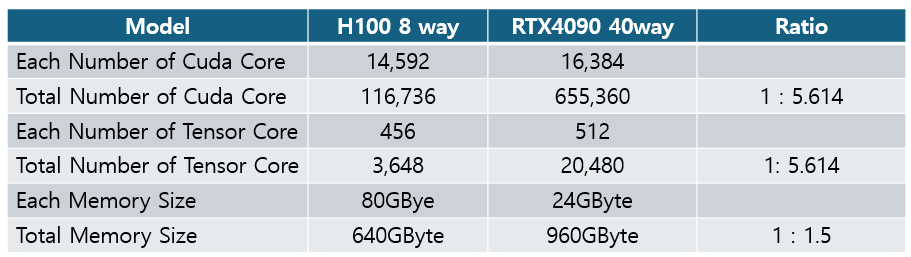
결론적으로 코어수는 5.6배가 넘고 메모리도 50%가 많아집니다. 예상되는 Overal Performance 는 최소 2~3배 정도 입니다.
물론 머신러닝, 시뮬레이션, 렌더링 등 사용 용도와 설정방식에 따라 실제 성능은 차이가 있을 수 있죠. NVLINK NVSWITCH 기술도 대단하기도 하구요
그럼에도 불구하고 코어수는 무시못합니다. GPU 를 사용하는 이유가 결국은 이 어마무시한 코어수를 이용한 단순 계산 일개미들의 잇점 때문이니까요.
이제 제가 생각하는 두가지 방식의 장단점을 나열해 보겠습니다.
1. 납품 기일 측면에서 H100 장비를 구하는건 오래 걸립니다. 물건을 구하기 쉽지 않죠. 요새 조금 시장이 좋아병瑁嗤통상적으로 몇십주가 걸립니다.
이에비해 Super GPU Box 는 게임용으로 쓰이는 RTX4090 을 사용하여 주문즉시 제작하고 납품하는것이 가능합니다.
2. 도입 비용 측면 에서 양쪽다 5~6억원 정도로 유사합니다. 서버의 사양차이가 있을 뿐이죠.
3. 설치장소 측면에서 H100 같은 엔터프라이즈 제품군은 데이터센터에 설치할 수 있고, 공간도 4U~8U 정도면 됩니다. 냉각을 포함한 전력은 대략 10Kw 이하로 필요합니다.
이에비해 Super GPU Box 에 사용되는 RTX4090 같은 리테일용 제품은 데이터센터에 설치하는 것이 엔비디아의 소프트웨어 라이선스 위반입니다. 드라이버 부터 SDK 등등 모두 데이터센터에 사용하는것을 금하고 있습니다. 하지만 Super GPU Box 는 항온항습방음방진랙 일체형입니다. 따라서 사무실이나 연구실 사내 전산실 등에 설치하는데는 제한이 없습니다. 엔비디아의 라이선스 정책을 보기좋게 빗겨나간거죠. 다만 풀랙 2개정도의 공간이 필요하고 냉각을 포함한 전력도 35KW 정도 필요합니다. H100 8way 에 비해 3배 이상 차이나죠.
4. 고속 스토리지 연결 측면에서 H100 8Way 가 유리합니다. 내장된 PCI-e 레인에 여유가 있으니 충분한 내장 스토리지를 장착하거나 다른 스토리지로 연결할 충분한 대역폭이 남아 있습니다. 이에비해 Super GPU Box 는 내장으로 사용한다면 최대 PCI-e 32Lane 과 기존의 SATA 포트들을 사용할 수 있고, 외장으로 연결시에도 400G 카드 두개 정도 장착이 가능합니다. 최대 800Gbps 인거죠.
이런 한계는 인정할 수 밖에 없습니다. Super GPU Box 는 일종의 Micro GPU Data Center 의 역할을 합니다. 특정한 서비스 런칭을 위해 개발하거나 고속 렌더링, 시뮬레이션을 조직 내부에서 실행하기에 적합한 사이즈입니다. 실제 대규모 서비스를 운영하는 용도로 보기는 어렵습니다. 그에 따른 시장 세그멘테션은 다음과 같습니다.

결과적으로 우리의 목표 시장은 다음과 같이 정해졌습니다.

그리고 추가적으로 우리가 중요하게 생각하는 시장이 있습니다.
군, 정보기관, 경찰, 병원, 공공기관, 검찰, 바이오 회사, 금융기관 등 자체 데이터를 이용한 머신러닝이 필요 하지만 외부에 데이터 노출이 어렵거나 불가능한 모든 프로젝트에 적용 가능하며, 전년도 책정 예산을 초과하는 시장가격 변동에도 안정적인 공급이 가합니다. 이런 특수시장은 항상 존재해 왔습니다.

우리는 이런 특수시장을 공략하기 위해 전세계 최고 레벨의 정보서비스를 각국 정부기관에 제공중인 코그나이트 사와 공신력을 갖춘 사이버안보연구소 의 3자 협약을 통해 특수시장을 개척하고 있습니다.
제품에 대한 문의사항이 있으시면 언제든지 쪽지 주십시요.
멋지게 나온것 같습니다.
소음도 적을 것 같은데요.
수요가 많이 있을 것 같습니다.
저도 협력 Agency 를 해야 겠네요.
침실처럼 정숙을 요구하는게 아닌 이상 일정한 수준의 화이트 노이즈가 유지되는건 큰 문제가 안 됩니다
커널 리빌드해서 인식시켰나요 ?^^
보통 저런 돼지같은 장치 40개나 물리면 부트자체가 안 되요
안 만져봤으면..
대단합니다.
지금 블랙웰 나오는것 보면 GPU에 4.0 x16으로 죄다 시퓨 직결해놔도 대역폭이 충분하지 않다는 생각이 들정도거든요 (PCIe의 근본적 대역폭 문제도 있고, 구조상 각각이 모두 병목 없이 상호 연결될 수 도 없음)
~400G까지 NIC를 연결 가능한 시점에서 Storage는 큰 문제가 아니라고 봅니다 (온보드 10기가로 일반적 통신을 처리하고, 저 2개로 연결 (서버를 상호 연결한다는 선택지도 있겠지만, 대부분의 경우 40GPU정도면 충분할꺼고, 물리적으로 렉을 복수 배치할만큼 공간을 확보하기도 힘들죠)하면 충분하다고 봅니다)
저정도 성능을 독립적 시스템으로 완벽하게 운영할 수 있다는 큰 장점이 된다고 봅니다
물론 엔디비아 GH200 랙 처럼 하나의 GPU 처럼 쓰는건 안되도 유사한 효과는 기대할수 있죠 모델 데이터 다 분할하니.
추가적으로 100레인 스위치 칩이라 내부 5개는 x16으로 서로 통신하고 부족하더라도 다른 수가 없죠. 업링크? 도 x16 입니다. x4 가 남죠.. 사실 144레인 스위치칩도 있습니다만, 4슬롯 GPU의 한계로 더이상 불필요 해서 100레인을 사용합니다. 업링크를 더 줄수도 있지만 어차피 서버 자체의 레인도 80레인 듀얼 CPU 한계가 있어서 64레인만 쓰고 겨우 나머지 16레인이 남다보니 타협한거죠.
그리고 40개의 GPU 에 대해 최소 개당 2코어 메모리 20기가바이트는 줘야해서 80코어 800기가바이트 필요하니 48코어 듀얼에 1테라 정도 램이 최소 입니다.
GPU 40개라니 정말 대단합니다~^^
NVLink로 정말 빠른 대역폭으로 연결해서 메모리간 통신에 병목이 없네 어쩌네..
멜라녹스 NVLink 스위치 까지 해다가 노드끼리도 NVLink로 묶고..
물론 가격은... 어억 소리 나오죠..
저대로라면 PCI 5.0 8배속 정도가 한계 이겠군요.
흠..
근데 DGX 는 물건이 부족한데다가.. 돈있다고 살수 있는것도 아니고 최신은 더하죠..
억? ㅎㅎ NVSwitch 라는 단어가 들어가는순가 수십억입니다.
뭐 가격이라는데 있어서 뾰족한 수가 없으니 뭉툭한 수를 제안하는 거죠.
그나마도 엔비디아에서 만든 AI/데이터센터용 GPU 제품군은 구하기도 어려워서 구성하는데 시간이 오래걸린다고 들었습니다.
AI문외한인 제가 보더라도 중소규모 구성에서는 구하기 어려운 H100 보다는 본문처럼 그나마 구하기 쉬운 RTX 시리즈를 더 넣어서 구성하는것이
오히려 더 나아 보인다는 생각이 듭니다.
ㅎㅎ 불나겠습니다. 웬만한 사무실이면 전기공사부터 해야 하지 않을까 싶네요.
이거 군사무기쪽으로는 못쓰려나요?
이지스같은 함정전투체계에 적용하거나 에이사레이더에 붙여서 해상도향상, 노이즈제거에 좋을것같은데요.
질문은 40개의 GPU가 메인 보드 하나에 연결되는데 scalability가 제일 문제일 것 같습니다. 제가 RTX3080 4개를(PCIE 4.0) Resnet50 벤치시 GPU1개 대비 3.25배 성능이 나왔습니다. http://www.2cpu.co.kr/bmt/4040
4090 1개 대비 40배의 성능 향상이 오도록 소프트웨어적으로 어떤 조치를 하시나요?
감사드립니다.
결국. DDP 죠
지금의 벤치마크는 GPU 간 통신에 대해 따로 설정없이 깡으로 돌리는듯 합니다.
그게 아니라 40배가 나오려면? 모델과 데이터 분산을 통한 옵티마이징은 필수 입니다.
구조상 8개의 박스로 나누고 다시 각박스에서 5개의 GPU 에 분산하는게 필요합니다.
소음은 어느정도일까요?