

안녕하세요
노성훈 입니다.
3번째 강좌 입니다.
이번 강좌는 학습에 앞서서 학습 시킬
데이터에 대해 알아보겠습니다.
강좌는
3. 데이터 준비하기
4. MNIST For ML Beginners
5. Deep MNIST for Experts
순서로 진행될 예정입니다.
학습시킬 데이터는 MINIST Dataset 입니다.
이 데이터는 손으로 쓴 숫자를 학습시켜서
새로운 데이터가 들어왔을 때 어떤 숫자인지를 맞추는 것 입니다.
머신러닝에서는 유명한 데이터 셋이지요
데이터는 이러한 모양이고
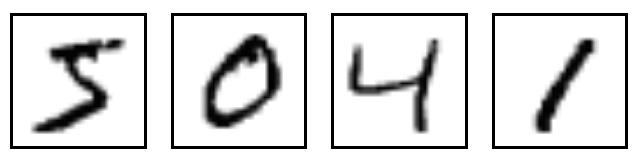
더 자세히 들여다보면 요런 그림 입니다.
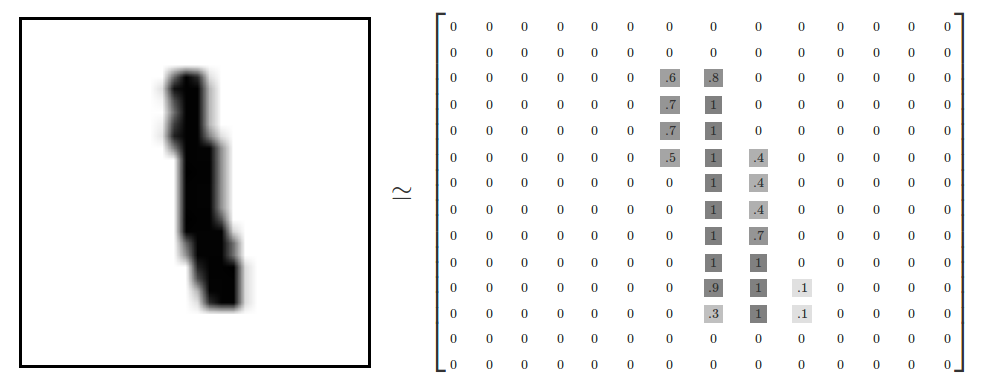
그림은 28 X 28 = 784개의 픽셀 정보로 저장되어 있습니다. 진할수록 1에 가깝고 없는 것은 0이 되지요.
실제로는 0~255의 값을 갖습니다.
그리고 각 정보에 대해서 이름표가 달려 있습니다. 위의 이미지의 경우에는 1 이라는 이름표가 달려있지요 (Label이라고 합니다.)
따라서 그림 하나에 저장된 데이터의 숫자는 785개 입니다.
이러한 정보가 70000개 준비되어 있고 이번 예제에서는
이중에 55000개를 학습용(training data)으로 10000개를 시험용(test data)으로 5000개를 검증용(validation data)으로 사용합니다.
학습시켜서 성능을 계산하는데 이러한 분류가 사용됩니다.
머신러닝이란 변수를 수정해 가면서 성능을 최적화 해 나가는 것이기 때문에
성능을 계산하는 것이 중요한 부분이지요
어떻게 학습시킨 모델의 성능을 계산 할 수 있을 까요?
제일 쉬운 방법으로는 모든 데이터를 학습에 사용하고 모델을 생성한 후 이를 통해 얻어진 데이터를 생성된 모델에 입력하여 성능을 계산하는 것 입니다.
그런데 여기는 함정이 있습니다.
입력한 데이터만 너무나 딱 맞게 모델이 생성되는 것이지요
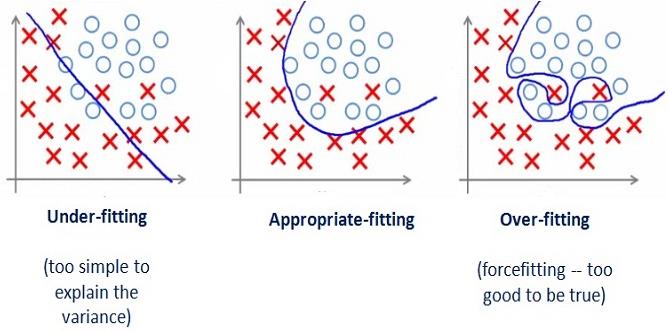
위 그래프에서 Over-fitting을 보시면 너무 특정한 파라메터에 맞게 분류가 된 것을 볼 수 있습니다. 사실 가운데 있는 X 부분에는 O가 올 확률이 더 높겠지요
이를 피하기 위해서 데이터를 3등분으로 나눕니다.
| Training | Validation | Test |
일반적으로 70:20:10 정도로 나눈다고 하는데 규칙으로 정해진 것은 없습니다.
이렇게 3등분으로 나누어진 데이터를 가지고 Training Data로 학습을 시키고 학습한 내용을 Validation data를 이용하여 점수를 매기고 점수를 올리는 방향으로 학습시키고 다시 점수를 매기고를 반복합니다.
이렇게 반복하게 되면 Validation data가 Training에 영향을 주는 효과가 나타나지만 Test data는 사용하지 않았기 때문에 Test data는 Over-Fitting에 영향에서 벗어나 있습니다.
최종적으로 모델을 결정할 때는 Validation 결과와 Test 결과를 이용하여 모델을 결정하게 됩니다.
다시 데이터로 돌아가서
이 데이터는 http://yann.lecun.com/exdb/mnist/ 사이트 에서 받을 수 있고 이 데이터에 대한 연구 결과도 같이 볼 수 있습니다.
각 Algorithm 별로 가장 좋은 것을 가져와서 보면 아래 표와 같습니다.
Algorithm | CLASSIFIER | PREPROCESSING | TEST ERROR RATE (%) | Reference |
Linear Classifiers | pairwise linear classifier | deskewing | 7.6 | LeCun et al. 1998 |
K-Nearest Neighbors | K-NN, shape context matching | shape context feature extraction | 0.63 | Belongie et al. IEEE PAMI 2002 |
Boosted Stumps | product of stumps on Haar f. | Haar features | 0.87 | Kegl et al., ICML 2009 |
Non-Linear Classifiers | 1000 RBF + linear classifier | none | 3.6 | LeCun et al. 1998 |
SVMs | Virtual SVM, deg-9 poly, 2-pixel jittered | deskewing | 0.56 | DeCoste and Scholkopf, MLJ 2002 |
Neural Nets | deep convex net, unsup pre-training [no distortions] | none | 0.83 | Deng et al. Interspeech 2010 |
Convolutional nets | committee of 35 conv. net, 1-20-P-40-P-150-10 [elastic distortions] | width normalization | 0.23 | Ciresan et al. CVPR 2012 |
데이터 마다 잘 맞는 알고리즘이 따로 있겠지만 이 데이터 셋에서 가장 성능이 좋은 것으로 알려진 것은
Convolutional nets 으로 에러율이 0.23% 입니다. 그리고 이 방법이 우리가 흔히 Deep learning 이라고 부르는 Neural network 입니다.
Neural network 이 무엇인지는 다음에 알아보고 오늘은 머신러닝에 사용되는 데이터가 어떤 것인지에 대해 집중해 보겠습니다.
다시 돌아가서 데이터를 다운로드 받으면 파일이 두개 입니다. (실제로는 Training data, Test data 각각 이미지와 라벨 파일이 있어 4개 입니다)
Label 파일 하나와 Image 파일 하나 이고 확장자가 idx3-ubyte 이고 더블 클릭해도 열리지 않습니다.
785개의 데이터가 들어 있을 것이라고 추정은 하는데 실제로 어떻게 생겼나 궁금해서 열어보도록 하겠습니다.
저는 ARTMONEY 라는 툴을 이용하여 파일을 열어 보았습니다.
라벨 파일의 정의는 아래와 같습니다.
TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
........
xxxx unsigned byte ?? label
The labels values are 0 to 9.
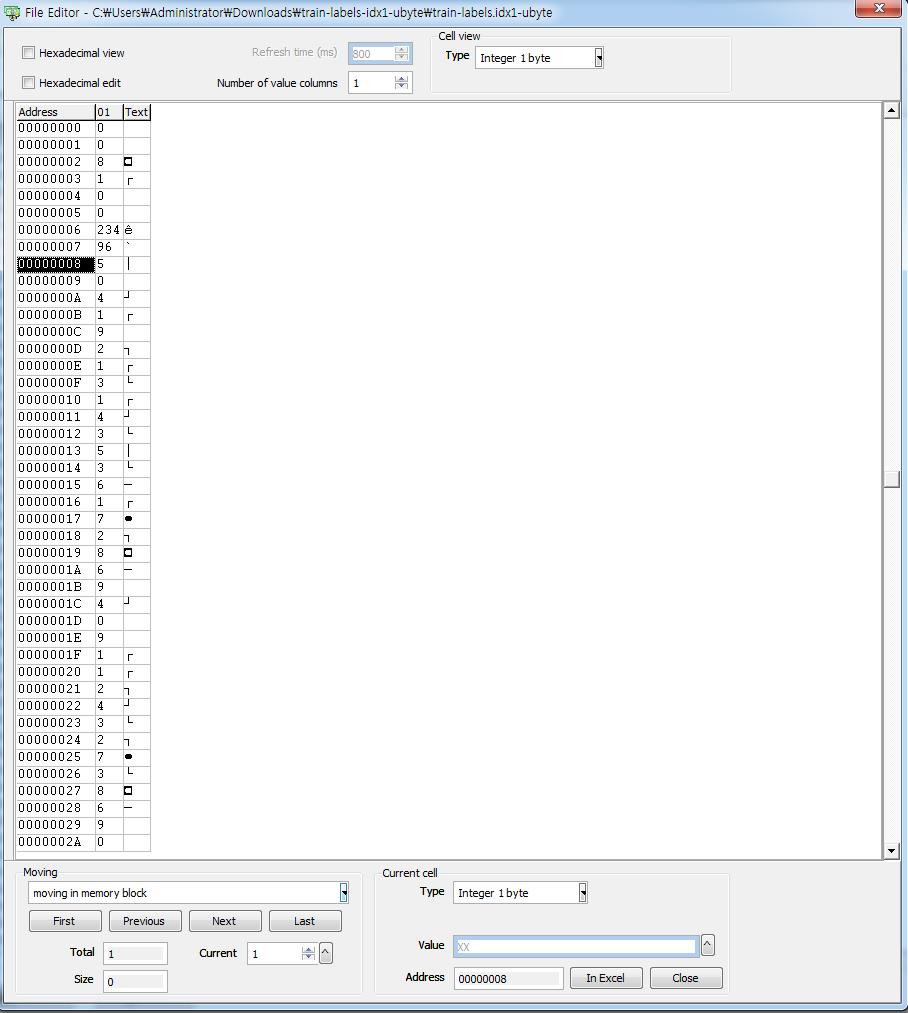
실제로 읽어보면 아래와 같이 읽히고 00000008 부터 숫자는 해당 이미지의 값 입니다.
00000008 이 첫 이미지를 나타내므로 첫 이미지의 값이 5 라는 뜻 입니다.
이미지 파일의 정의는 아래와 같습니다.
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
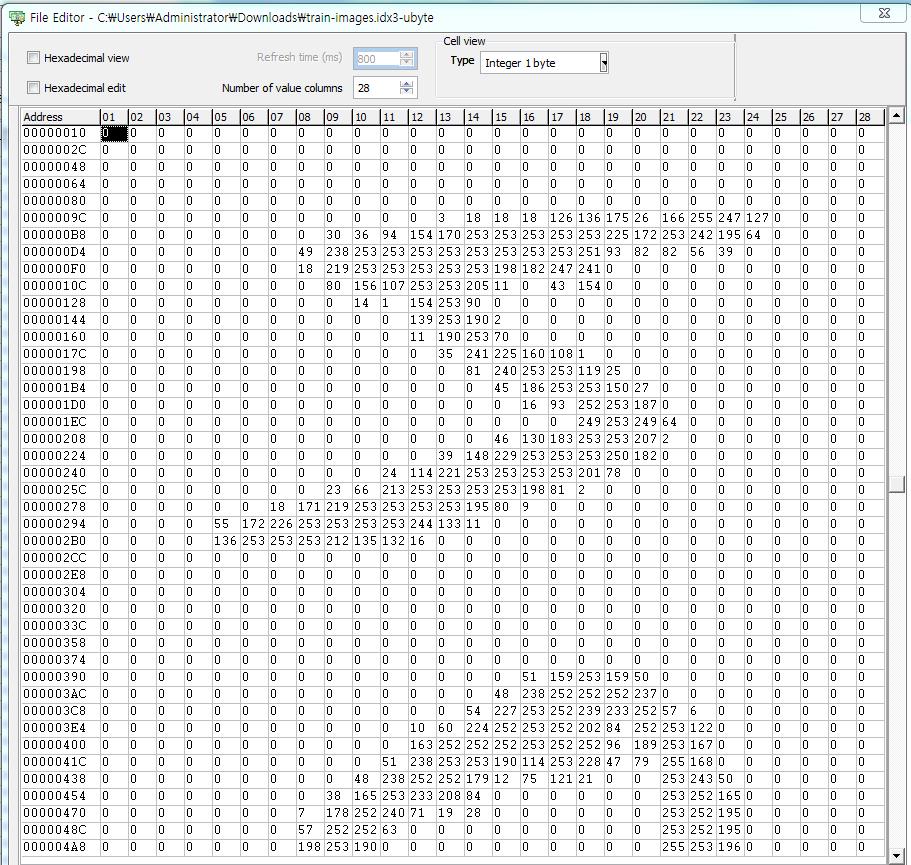
16번 주소부터 이미지 Pixel 값이 저장되어 있습니다. 헥사 주소로 바꾸면 00000010 입니다.
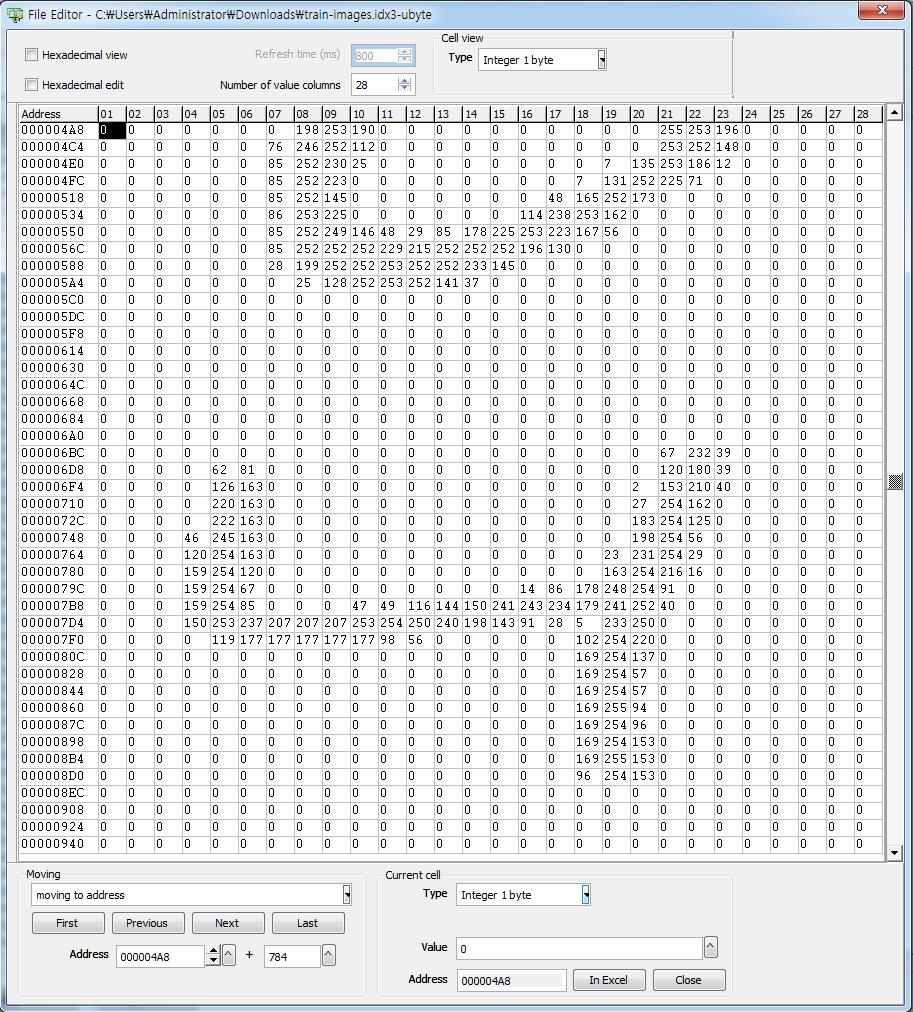
실제로 열어보니 숫자가 쭉 들어있고 들어있는 모양을 28 columns로 보정하니 숫자 모양이 보입니다.
예상한 것과 같이 28X28 의 숫자가 연달아서 쭉 들어 있습니다.
실제로 첫번째 이미지가 5라는 것도 확인이 가능합니다. 두번째는 0, 세번째는 4로 Label에 나와 있는 것과 같네요
이제 학습시킬 이미지와 그 이미지가 의미하는 것이 무엇인지 나타내는 Label 이 준비 되었습니다.
데이터가 준비 되었으니 이제 학습을 시켜야겠습니다.
학습은 다음 강좌에서 이어가겠습니다.
시너지가 엄청날 것 같습니다.
골드만 삭스 같은 곳은 하루에 저장되는 데이터가 5TB 라고 하더라구요
파일을 선택 하시고 Files->file editor를 선택하면 됩니다.