


안녕하세요
노성훈 입니다.
4번째 강좌입니다.
계속해서 공식사이트의 예제를 따라갑니다.
이제 앞에 설명한 MNIST 데이터를 가지고 학습을 해 보겠습니다.
입력 데이터가 어떤 숫자인지 알기 위해서는 어떻게 해야 할까요?
우리가 숫자를 인식할 때를 생각해보면 어떤 특정 위치에 색칠이 칠해져 있는 것을 우리는 숫자로 인식하고 인지할 수 있습니다.
컴퓨터도 마찬가지로 1을 예로 들어 생각해 보면 가운데 일자로 내려긋는 곳에 색칠이 되어 있는 것은 1이라는 증거가 확실해 지는 쪽이고 그 외의 부분에 색칠이 되어 있는 것은 1이 아니라는 증거가 확실해 지는 것 입니다.
이를 그림으로 표현 해 보면 이와 같습니다.
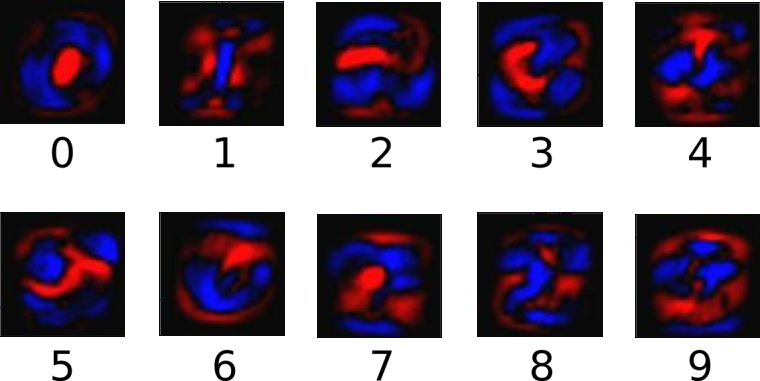
파란색에 색칠이 된다는 것은 해당 숫자일 가능성이 커지는 것이고 빨간색에 색칠이 된다는 것은 해당 숫자일 가능성이 감소하는 것 입니다.
한장의 이미지 데이터가 주어졌을 때 이것이 특정 숫자일 가능성은
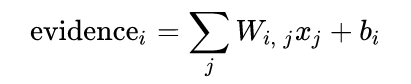 이렇게 나타낼 수 있습니다. Xj 에는 해당 픽셀의 값(0~255)이 들어가게 될 것이고 Wi,j,Bi 에는 숫자에 따라 다른 값이 들어가게 됩니다. (Weight, Bias 라고 부릅니다.)
이렇게 나타낼 수 있습니다. Xj 에는 해당 픽셀의 값(0~255)이 들어가게 될 것이고 Wi,j,Bi 에는 숫자에 따라 다른 값이 들어가게 됩니다. (Weight, Bias 라고 부릅니다.)
i는 숫자를 의미합니다. Evidence0 이라 하면 이 그림이 숫자 0을 의미 하는 증거 라는 뜻이고 증거 값이 클수록 해당 숫자라는 확신이 더 커지는 것이지요
j 는 픽셀을 나타냅니다. 우리 그림은 28X28 이므로 0~783 이 됩니다.
W는 10X784 행렬로 표현할 수 있고
B는 10X1 행렬로 표현할 수 있습니다.
그리고 이렇게 얻어진 증거값을 해당숫자일 확률을 구하는 함수에 입력합니다.
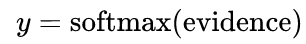
여기서는 Softmax 라는 함수를 사용하는데요
Softmax를 식으로 나타내면 아래 식이고
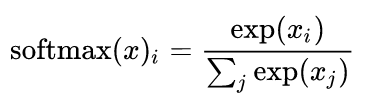
일단 증거값을 넣으면 확률로 계산이 된다 정도로 알고 넘어 가겠습니다.
입력값이 주어지면 Weight 곱하고 Bias를 더한 후 각 숫자일 확률을 구하는 것을 그림으로 표현하면 아래와 같습니다.
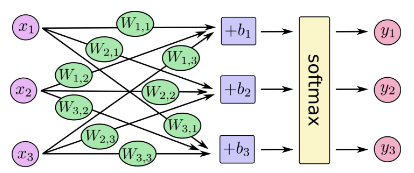
행렬로 나타내면 아래와 같고요
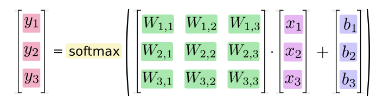
우리는 위 행렬 조합으로 이미지를 입력하여 Y 값을 만들어 낼 수 있게 되었습니다.
그리고 그 값이 맞는지 틀리는지를 그림에 Label을 통해 판단할 수 있습니다.
(Label 데이터에는 0~9의 숫자로 저장되어 있는데 이것을 One-Hot encoding을 통해 10bit의 Binary 값으로 변환해서 사용하면 위 행렬과 같은 그림이 됩니다)
학습은 결국 알고 있는 값과 가장 유사한 W,b값을 구하는 것 이라고 할 수 있겠습니다.
그 방법은 W,b를 계속 바꾸면서 오차율을 측정하고 오차가 작아지는 방향으로 변경해 나가는 것 입니다.
이제 코드로 넘어가 보겠습니다.
먼저 데이터를 다운로드 합니다. 데이터는 Image, label 2가지 입니다
Python을 실행시키고 아래 명령어를 입력합니다.
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
학습 코드는 매우 간단합니다.
import tensorflow as tf
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
결과는 이렇습니다.
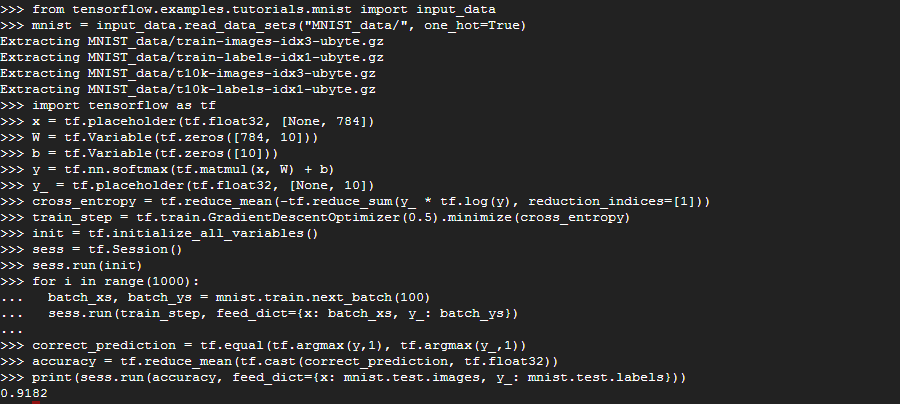
몇 줄 안되는 코드로 90% 이상의 정확도를 갖는 모델을 학습할 수 있습니다.
코드를 분석해 보겠습니다.
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
그림 정보를 저장할 변수를 x로, Weight, Bias 정보를 저장할 공간을 각각 W,b 로 선언합니다.
y = tf.nn.softmax(tf.matmul(x, W) + b)
Y는 예측 결과 입니다.
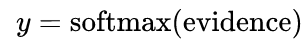
이 식을 표현했습니다.
y_ = tf.placeholder(tf.float32, [None, 10])
우리가 알고있는 Label 이 저장될 공간입니다.
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
우리는 입력한 데이터에 대해 예측결과와 실제 데이터의 차이를 최소화 해야 합니다.
이를 수식으로 나타내면
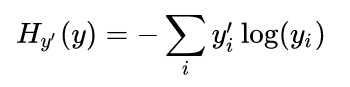 으로 Cross-entropy 라는 cost function 입니다.
으로 Cross-entropy 라는 cost function 입니다.
이것이 작을수록 두 값이 유사하다는 뜻이 됩니다.
위의 코드는 이 식을 표현한 것 입니다.
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
init = tf.initialize_all_variables()
이제 위의 Cross-entropy를 작게 만들도록 학습을 시키는 코드입니다.
여기서는 경사 하강법을 사용해서 목표값을 찾아가는 동작을 합니다.
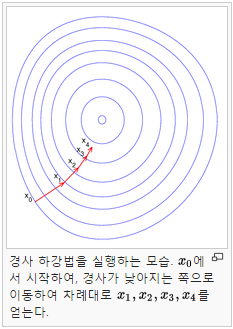
0.5의 Step 크기로 cross_entropy 를 최소화 하는 방향으로 동작하게 됩니다.
이 step의 크기를 learning rate 라고 하는데 이 값이 너무 크면 학습이 잘 안되고 너무 작으면 학습이 느려지게 됩니다.
경사하강법 외에도 AdagradOptimizer, MomentumOptimizer 을 사용 할 수 있습니다.
init = tf.initialize_all_variables()
변수들을 초기화 해 줍니다.
sess = tf.Session()
sess.run(init)
run 에서 실제 수행이 일어나게 됩니다.
초기화를 수행합니다.
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
실제 학습이 실행됩니다
100개씩의 랜덤 데이터를 학습하는 함수에 입력하는 것을 1000번 수행합니다.
모든 데이터를 매번 하면 좋지만 시간이 많이 들기 때문에 선택한 방법입니다.
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
학습 결과가 실제 label 과 얼마나 같은지 검증합니다.
맞는지 틀린지가 [True, False, True, True] 형식으로 correct_prediction 저장되고 이것을 평균 내서 맞을 확률을 구해줍니다.
이번코드는 90%대의 정확도가 나옵니다.
다음은 이 코드를 조금 수정해서 정확도를 올리겠습니다.
근데 외계어인가요 ㅋㅋㅋ
자연어 학습에 많은 도움 되고 있습니다~~~~
채워주시는군요.. 이런 강좌 너무 감사해요.
배울수록 재미있는 분야인것 같습니다.
이렇게 친절히 설명해주시고.. 아무튼...
목적하신 바 꼭 이루시길 바랍니다 ^^
재미있으셨으면 좋겠습니다.
요즘 컴퓨터 비전쪽 PM을 보고 있습니다.
공정표를 보면 지금 연구소에서 SVM을 학습시키고 있는데요.
적어주신 강좌가 비 전공자인 제게 개념잡는데 많은 도움이 되고 있습니다 ^^